
첫 페이지 부터 내 시선을 사로잡은 그림.
지금까지의 내 모습이었다.
바로 그 아래 내가 혼공족을 시작한 이유가 나왔다.
이 두장의 그림이 공감을 일으켜 웃음이 나오기도 했고, 다시 한번 공부 의지를 다지게 해주었다.
Ch 01. 컴퓨터 구조 시작하기
학습 목표
- 컴퓨터 구조를 왜 알아야 하는지 이해합니다.
- 컴퓨터 구조의 큰 그림을 그려봅니다.
컴퓨터의 구조
컴퓨터는 크게 컴퓨터가 이해하는 정보와 컴퓨터의 핵심 부품으로 나누어진다.
컴퓨터가 이해하는 정보
데이터(Data)
- 컴퓨터가 이해하는 숫자, 문자, 이미지, 동영상 같은 정적인 정보.
명령어(Instruction)
- 데이터를 움직이고 컴퓨터를 작동시키는 정보
컴퓨터에 저장된 사진파일, 텍스트 등은 모두 데이터고, 마우스로 클릭해서 열고 삭제하는 행동이 명령어가 된다고 이해했다.
컴퓨터의 핵심 부품
중앙처리장치(CPU, Central Processing Unit)
- 메모리에 저장된 명령어를 읽고 해석하고 실행하는 부품
- 컴퓨터의 두뇌
- 내부 구성요소
- 산술논리연산장치(ALU, Arithmetic Logic Unit): 계산기.
- 레지스터(Register): 프로그램 실행을 위해 필요한 값을 임시 저장.
- 제어장치(CU, Control Unit): 명령어를 해석하고, 제어신호를 보내 부품을 관리하고 작동시킴
주기억장치(Main memory)
- 실행되는 프로그램의 명령어와 데이터를 저장하는 부품
- 프로그램이 실행되려면 반드시 메모리에 저장되어있어야 함
- 주소(Address)
- 메모리에 저장된 값에 빠르고 효율적으로 접근하기 위해 사용하는 개념
- 매번 메모리 전체를 검색하지 않고 가지고있는 주소에 바로 접근 가능.
- 단점
- 가격이 비싸서 저장 용량이 적음
- 전원이 꺼지면 저장된 모든 내용이 사라짐
보조기억장치(Secondary storage)
- 메모리의 단점을 보완하기 위한 저장 장치
- 메모리보다 크기가 크고 전원이 꺼져도 저장된 내용을 잃지 않음
- ex) 하드 디스크, SSD, USB, DVD, CD-ROM
입출력장치(I/O device, Input/Output device)
- 컴퓨터 외부에 연결되어 컴퓨터 내부와 정보를 교환하는 장치
- ex) 키보드, 마우스, 스피커, 프린터
메인보드: 여러 컴퓨터 부품을 부착할 수 있는 슬롯과 연결 단자가 있는 판
버스: 메인보드에 연결된 부품들이 서로 정보를 주고받을 수 있게 연결해주는 통로
Ch 02. 데이터
학습 목표
- 컴퓨터가 이해하는 정보 단위를 이해합니다
- 0과 1로 다양한 숫자를 표현하는 방법을 이해합니다.
- 0과 1로 다양한 문자를 표현하는 방법을 이해합니다.
정보 단위
비트(Bit)
- 0과 1을 나타내는 가장 작은 정보 단윈
- n개의 비트는 2^n가지 정보를 표현 가능
| 1byte | 8bit |
| 1kB | 1,000byte |
| 1MB | 1,000kB |
| 1GB | 1,000MB |
| 1TB | 1,000GB |
크기 순서
비트(Bit) < 바이트(Byte) < 킬로바이트(KB, Kiobyte) < 메가바이트(MB, Megabyte)
< 기가바이트(GB, Gigabyte) < 테라바이트(TB, Terabyte)
- 이전 단위를 1,000개 묶어서 그 다음 높은 단위를 표현
- 이전 단위를 1,024개 묶어 표현한 단위는 KiB, MiB, GiB, TiB로 표현
워드(Word)
CPU가 한 번에 처리할 수 있는 데이터 크기.
CPU마다 워드 크기가 달라진다.
진법
| 진법 | 사용하는 숫자 | 해당 진법으로 표현한 수 | 20을 표현하는 방법 |
| 이진법(Binary) | 0, 1 | 이진수 | 10100(2) |
| 십진법(Decimal) | 0 ~ 9 | 십진수 | 20 |
| 십육진법(Hexadecimal) | 0 ~ 9, A ~ F | 십육진수 | 14(16) 또는 0x14 |
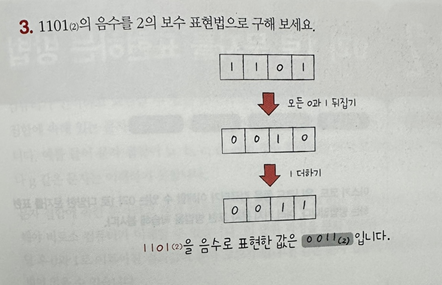
2의 보수(Two's complement)
- 이진수의 음수 표현에 가장 많이 사용되는 방법
- 어떤 수를 그보다 큰 2^n에서 뺀 값을 의미
- ex) 11(2)의 2의 보수
- 2^n -> 100(2)
- 100(2) - 11(2) = 01(2)
- 모든 0과 1을 뒤집고 1을 더한 값과 같다.
- 단점
- 음수인지 양수인지 구분하기 어려움
- 1000(2)에 2의 보수를 취하면 자기자신인 1000(2)가 되는 문제
십육진수 <-> 이진수 변환
- 이진수<->십육진수간 변환이 쉽기 때문에 십육진수를 사용한다.
- 십육진수 한 글자를 4bit의 이진수로 변환 후 이어붙인다.
- ex) 1A2B(16)
- 1(16) -> 0001(2)
- A(16) -> 1010(2)
- 2(16) -> 0010(2)
- B(16) -> 1011(2)
- 1A2B -> 0001101000101011(2)
- 이진수 숫자를 4개씩 끊어 십육진수로 변환 후 이어붙인다.
- ex)11010101(2)
- 1101(2) -> D(16)
- 0101(2) -> 5(16)
- 11010101(2) -> D5(16)
문자 집합과 인코딩
문자 집합(Character set)
- 컴퓨터가 인식하고 표현할 수 있는 문자의 모음
- 종류
- 아스키 코드(ASCII: Amerian Standard Code for Information Interchange)
- 7bit로 표현. 0 ~ 127까지 총 128개
- 매우 간단하게 인코딩 되지만, 표현할 수 있는 언어의 제한이 있음
- 8bit로 표현하는 확장 아스키(Extental ASCII)가 등장했지만 여전이 부족함
- 유니코드(Unicode)
- 대부분의 나라 문자, 특수문자를 코드로 표현할 수 있는 통일된 문자 집합.
- 다양한 방법으로 인코딩 가능. ex) UTF-8, UTF-16, ...
- 아스키 코드(ASCII: Amerian Standard Code for Information Interchange)
문자 인코딩(Character encoding)
- 컴퓨터가 이해할 수 있도록 문자를 0과 1로 변환하는 과정
- 종류
- 완성형
- 완성된 하나의 글자에 고유한 코드를 부여하는 방식
- ex) 가=1, 나=2, 다=3, ...
- 종류
- EUC-KR
- 조성, 중성, 종성이 모두 결합된 한글 단어에 2byte크기의 코드를 부여
- 모든 한글 조합을 표현할 수 없음.
- EUC-KR
- 조합형
- 초성, 중성, 종성마다 비트열을 할당하고, 그 조합으로 하나의 글자를 완성하는 방식
- ex) ㄱ=0010, ㅏ=0011, ㅐ=0001 00011 -> 강 = 0010 0011 0001 00011
- 완성형
문자 디코딩(Character decoding)
- 0과 1로 이루어진 문자 코드를 사람이 이해할 수 있는 문자로 변환하는 과정
Ch 03. 명령어
학습 목표
- 고급 언어와 저급 언어의 차이를 이해합니다.
- 컴파일 언어와 인터프리터 언어의 차이를 이해합니다.
- 명령어를 구성하는 연산 코드와 오퍼랜드에 대해 학습합니다.
- 명령어의 주소 지정 방식에 대해 학습합니다.
고급 언어와 저급 언어
고급 언어(High-level programming language)
- 사람이 이해하고 작성하기 쉽게 만들어진 언어
저급 언어(Low-level programming language)
- 컴퓨터가 직접 이해하고 실행할 수 있는 언어
- 종류
- 기계어
- 0과 1로 이루어진 명령어 모음
- 가독성을 위해 십육진수로 표현하기도 함
- 어셈블리어(Assembly language)
- 기계어를 읽기 편한 형태로 번역한 언어
- ex) 0101 0101 -> push rbp
- 프로그램이 작동하는지를 근본적인 단계에서부터 추적, 관찰이 가능함
- 기계어
컴파일 언어와 인터프리터 언어
컴파일 언어
- 컴파일러에 의해 소스 코드 전체가 저급 언어로 변환되어 실행되는 고급 언어.
- 변환 시, 컴파일러가 소스 코드 전체를 훑어봄.
- 목적 코드(Object code): 컴파일러를 통해 저급 언어로 변환된 코드
- ex) C언어
인터프리터 언어
- 인터프리터에 의해 소스 코드 한 줄씩 저급 언어로 변환되어 실행되는 고급 언어
- 오류 발생 시, 오류발생 직전 코드까지 실행
- ex) Python
명령어의 구조
연산 코드(Operation code)
- 명령어가 수행할 연산
- ex) 데이터 전송, 산술/논리 연산, 제어 흐름 변경, 입출력 제어
오퍼랜드(Operand)
- 연산에 사용할 데이터가 저장된 위치.
- ex) 데이터, 메모리, 레지스터 주소
주소 지정 방식
- 연산에 사용할 데이터 위치를 찾는 방법
즉시 주소 지정 방식
- 연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시하는 방법
- 가장 간단한 형태의 주소 지정 방식.
- 표현할 수 있는 데이터의 크기가 작아짐
- 연산에 사용할 데이터를 찾는 과정이 없어서 속도가 빠름
직접 주소 지정 방식
- 유효 주소를 오퍼랜드 필드에 직접 명시하는 방식
- 유효 주소: 연산의 대상이 되는 데이터가 저장된 위치
- 표현할 수 있는 데이터의 크기는 즉시 주소 지정 방식보다 큼
- 오퍼랜드 필드의 길이가 연산 코드의 길이만큼 짧아져 유효 주소에 제한이 생김
간접 주소 지정 방식
- 유효 주소의 주소를 오퍼랜드 필드에 명시
- 직접 주소 지정 방식보다 표현할 수 있는 유효 주소의 범위가 더 넓어짐
- 메모리에 2번 접근하기 때문에 속도가 느림
레지스터 주소 지정 방식
- 연산에 사용할 데이터를 지정한 레지스터를 오퍼랜드 필드에 직접 명시
- 메모리보다 레지스터에 접근하는 방법이 더 속도가 빠름
- 표현할 수있는 레지스터 크기에 제한이 생길 수 있음
레지스터 간접 주소 지정 방식
- 연산에 사용할 데이터를 메모리에 저장하고 해당 유효 주소를 저장한 레지스터를 오퍼랜드 필드에 명시
- 간접 주소 지정 방식과 비슷하지만, 메모리에 접근하는 횟수가 1번으로 줄어 듦.
기본 미션
p51 확인 문제 3번

p.65 확인 문제 3번
선택 미션
p.100의 스택과 큐의 개념 정리
스택과 큐
스택 개념 한 쪽 끝에서만 자료를 넣고 뺄 수 있는 LIFO(Last In First Out)형식 제한적으로 접근할 수 있는 나열식 구조 사용 사례 재귀 알고리즘 웹 브라우저 방문 기록 ex)뒤로 가기 큐(Queue) 개념 컴
tea-rrr.tistory.com